Curious case of Martian traffic
At FastNetMon we work with UDP based protocols such us Netflow, IPFIX and sFlow on daily basis.
These protocols are used by great variety of network equipment vendors to send information about traffic observed by network device to monitoring software.
Today our technical support team received report from customer about issue with receiving Netflow traffic.
As the very first step our support decided to check that VM with FastNetMon actually receives Netflow traffic and tcpdump helps us with such cases:
sudo tcpdump -n -i eth0 'port 2055' -c 1
18:27:28.186333 IP 0.0.0.0.2055 > a.b.c.d.2055: UDP, length 1400
We clearly can see that machine receives traffic over port 2055 and FastNetMon must receive it.
Sadly FastNetMon does not observe any UDP traffic over port 2055:
sudo fcli show system_counters |grep netflow_all_protocols_total_flows_speed
netflow_all_protocols_total_flows_speed 0
We clearly can see that it listens on port:
sudo netstat -lnpu
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp6 0 0 :::2055 :::* 44283/fastnetmon
What is the issue?
For all dropped UDP traffic Linux kernel has counters in netstat -su:
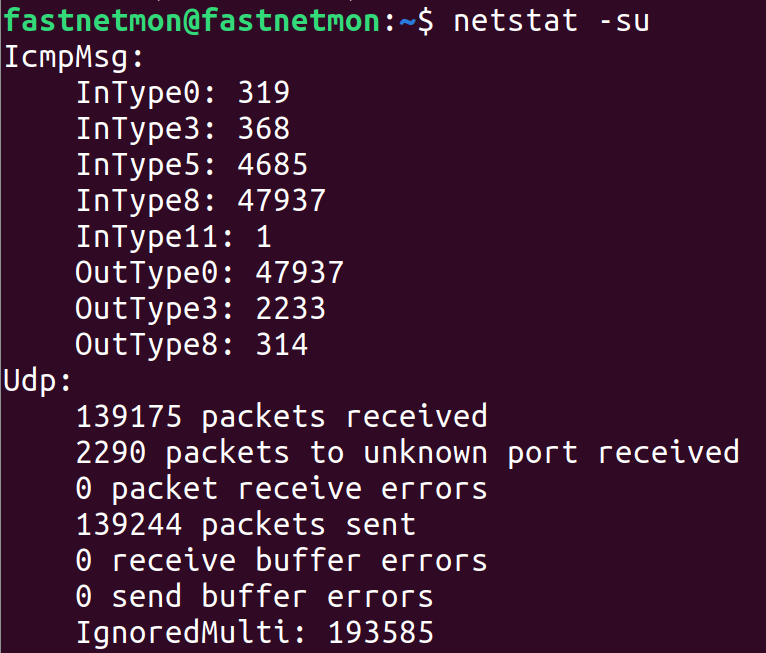
After running this command multiple times we cannot see any counters increasing and clearly our dropped UDP traffic towards port 2055 is not counted here.
The issue with tcpdump that it can see a lot of traffic which will be discarded by Linux kernel on next stages of packet processing pipeline and it was definitely the case.
For example if you have iptables rule which drop specific traffic tcpdump will see it but application will not receive it.
We've checked that machine has no iptables and last remaining suspect is Linux network stack. Let's dig deeper.
You may notice that traffic is coming from quite strange IP address which is 0.0.0.0 and device which generates it clearly located somewhere outside as it's separate physical box.
This IP belong to special purpose range 0.0.0.0/8 which even has name "This network":

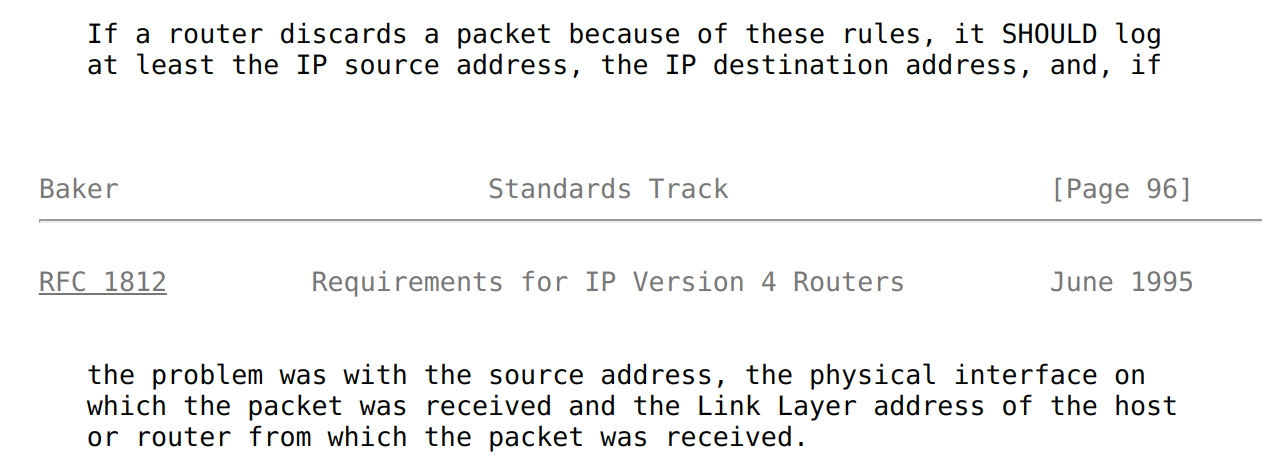
According to RFC 1812 any traffic coming from this range must be dropped unless it's coming from localhost / loop interface:

That's exactly what Linux kernel does.
Even more interesting that in next section of RFC we have mention that implementation must provide option to log such so called martian packets (or simply martians):
Clearly Linux is RFC compliant and we have flag which controls behaviour of this logic. We can enable logic to print all discarded martians to dmesg this way:
sudo sysctl net.ipv4.conf.all.log_martians=1
After making this configuration change we immediately see information about dropped traffic in dmesg:

Do we have any better ways to find such traffic without making any changes to Linux kernel configuration?
I found such way during my Linux kernel source code review:
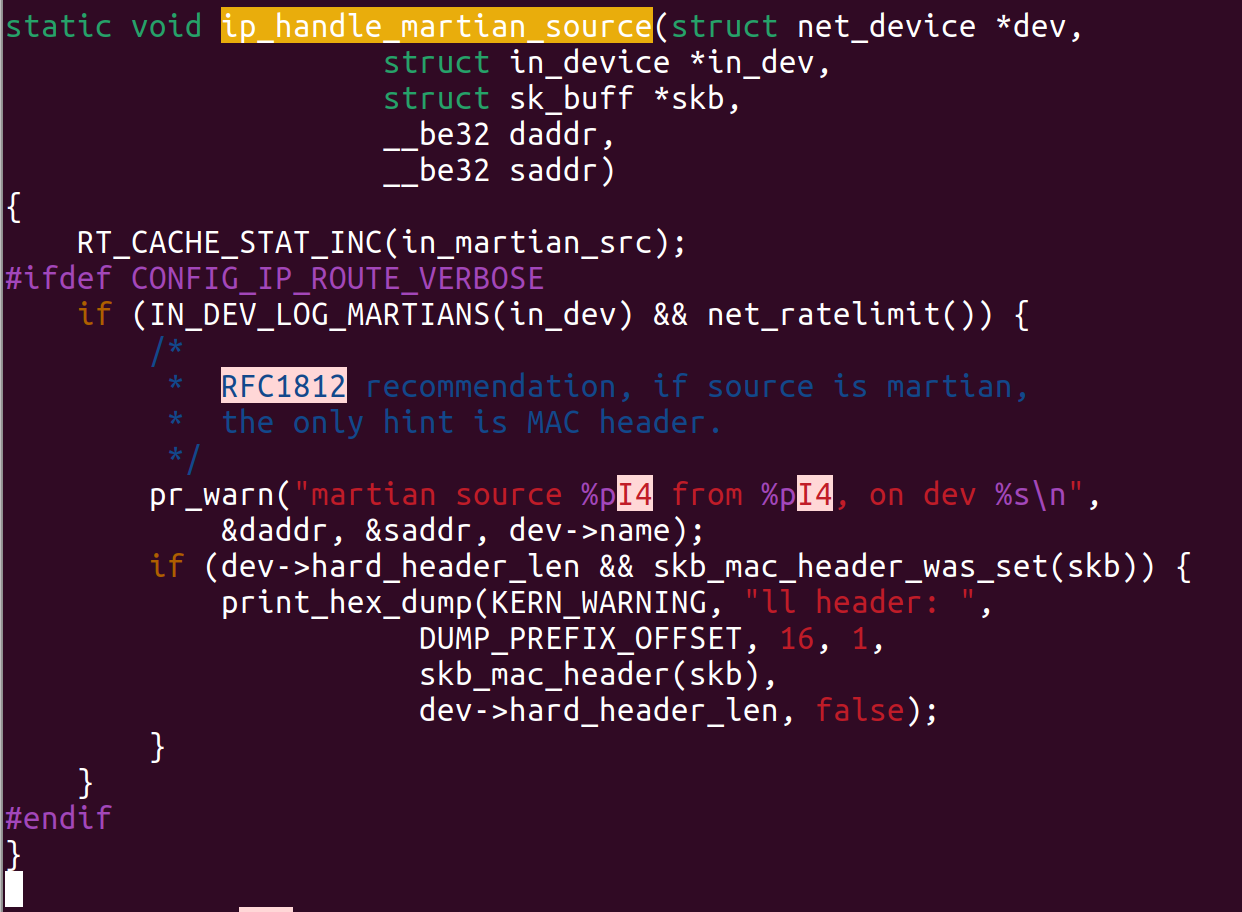
RT_CACHE-STAT_INC clearly increases counter with name in_martian_src when it observes martian traffic.
And you can easily read value of this counter using tool lnstat:
lnstat -k in_martian_dst,in_martian_src -w 20 -c 1
rt_cache| rt_cache|
in_martian_dst| in_martian_src|
0| 198940723|
It's relatively tricky to read as text and you may prefer to look on screenshot of my console:

That clearly pinpoints root cause and provides reason why millions of UDP packets to port 2055 were dropped.
What is the fix? The best way to fix this issue is to change Netflow / IPFIX / sFlow agent configuration on device to use another legitimate IP address instead of 0.0.0.0.